Using ML Clustering Algorithms
To Classify NBA Player Positions
December 2019
Introduction
With more and more big men extending their shooting range, coupled with the small-ball revolution, the NBA’s traditional five positions are arguably becoming more and more obselete. Players well over the average point guard height of 6’3″ such as Giannis Antetokounmpo and even LeBron James are defying old-school conventions by playing point guard/forward, and my goal was to let the machines decide whether or not we still need positional delineations.

Machine learning is a sub-discipline of artificial intelligence and computer science that deals with training models to make predictions based off input data. Clustering is an ML classification method that divides data into smaller groups, or clusters.
DBSCAN Clustering
The first algorithm, which stands for density-based spatial clustering of applications with noise, classifies players based on the density of their various statistics. In a 2D graph, this corresponds to forming classes based data points that are close in proximity to each other. For the NBA dataset, the model classified players into 10 clusters based on points, assists, offensive/defensive rebounds, steals, blocks, field goal attempts, field goal percentage, three-point attempts, three-point percentage, free throw attempts, and free throw percentage. The 3D graph to the right shows the different clusters, differentiated by color.
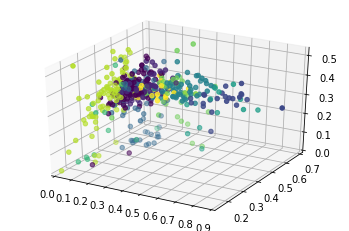
Final Positional Clusters (DBSCAN Model)
Paul George
LeBron James
Stephen Curry
Kawhi Leonard
Devin Booker
Kevin Durant
Damian Lillard
Kemba Walker
Bradley Beal
Blake Griffin
Donovan Mitchell
Kyrie Irving
Zach LaVine
Russell Westbrook
Jrue Holiday
Luka Dončić
DeMar DeRozan
D’Angelo Russell
Mike Conley
John Wall
Lou Williams
Trae Young
Victor Oladipo
Jimmy Butler
De’Aaron Fox
Chris Paul
Kyle Lowry
James Harden
Giannis Antetokounmpo
Joel Embiid
Anthony Davis
Karl-Anthony Towns
Julius Randle
LaMarcus Aldridge
Nikola Vučević
Nikola Jokić
Andre Drummond
Ben Simmons
DeMarcus Cousins
Jusuf Nurkić
Steven Adams
Myles Turner
Scott Machado
Klay Thompson
CJ McCollum
Buddy Hield
JaKarr Sampson
Tobias Harris
Danilo Gallinari
Lauri Markkanen
Kyle Kuzma
Khris Middleton
Brandon Ingram
Jamal Murray
Tim Hardaway
J.J. Redick
Andrew Wiggins
Bojan Bogdanović
Derrick Rose
T.J. Warren
R.J. Hunter
Kevin Love
Pascal Siakam
Jordan Clarkson
Spencer Dinwiddie
Collin Sexton
Josh Richardson
Harrison Barnes
Eric Gordon
Aaron Gordon
Jayson Tatum
Malcolm Brogdon
Dennis Schröder
Reggie Jackson
Jeremy Lamb
Kelly Oubre
Nikola Mirotić
Terrence Ross
Evan Fournier
Dwyane Wade
Emmanuel Mudiay
Jabari Parker
Bobby Portis
Bogdan Bogdanović
Marcus Morris
Goran Dragić
Rudy Gay
Taurean Waller-Prince
Carmelo Anthony
Jaylen Brown
Cedi Osman
Kevin Knox
Jae Crowder
Eric Bledsoe
Walt Lemon
Otto Porter
Caris LeVert
Dennis Smith
Marc Gasol
Robert Covington
Ricky Rubio
Thaddeus Young
Justise Winslow
Trevor Ariza
Jeff Teague
Joe Ingles
Kent Bazemore
Josh Jackson
Gordon Hayward
Kris Dunn
Darren Collison
Fred VanVleet
Shai Gilgeous-Alexander
Elfrid Payton
Justin Holiday
Derrick White
Lonzo Ball
Larry Nance
Nicolas Batum
Rajon Rondo
Tomáš Satoranský
Marcus Smart
Delon Wright
DeAndre’ Bembry
Mikal Bridges
Kyle Anderson
Patrick Beverley
Draymond Green
P.J. Tucker
Tyus Jones
Cory Joseph
Shaquille Harrison
De’Anthony Melton
John Collins
Montrezl Harrell
Deandre Ayton
Jonas Valančiūnas
Serge Ibaka
Marvin Bagley
Domantas Sabonis
Jaren Jackson
Enes Kanter
Al Horford
Jerami Grant
Paul Millsap
Brook Lopez
Hassan Whiteside
JaVale McGee
Willie Cauley-Stein
Derrick Favors
Alex Len
Jarrett Allen
Taj Gibson
Dewayne Dedmon
Thomas Bryant
Kenneth Faried
Wendell Carter
Cody Zeller
Jonathan Isaac
Bam Adebayo
Noah Vonleh
Mason Plumlee
Jemerrio Jones
Joe Harris
Gary Harris
Jeff Green
Wesley Matthews
Dion Waiters
E’Twaun Moore
Bryn Forbes
D.J. Augustin
Will Barton
Kentavious Caldwell-Pope
Reggie Bullock
Malik Beasley
Rodney Hood
DeMarre Carroll
Allonzo Trier
J.J. Barea
Tyler Johnson
Trey Burke
Damyean Dotson
Dario Šarić
Marco Belinelli
Monte Morris
Danny Green
Wayne Ellington
Tyreke Evans
Marvin Williams
Kelly Olynyk
Patty Mills
Kadeem Allen
Avery Bradley
Kevin Huerter
Luke Kennard
Allen Crabbe
Jeremy Lin
Nemanja Bjelica
Tony Parker
Al-Farouq Aminu
Markieff Morris
Shabazz Napier
Danuel House
Jalen Brunson
Alex Caruso
Gerald Green
Landry Shamet
Terry Rozier
Malik Monk
Ish Smith
Mario Hezonja
Alec Burks
Norman Powell
Frank Kaminsky
Kyle Korver
Rodions Kurucs
Trey Lyles
Langston Galloway
Bruno Caboclo
Darius Miller
Isaiah Thomas
Austin Rivers
Dāvis Bertāns
Jamal Crawford
Garrett Temple
Josh Hart
James Johnson
Josh Okogie
George Hill
Rodney McGruder
Shelvin Mack
Iman Shumpert
Chandler Parsons
Vince Carter
Lance Stephenson
Luke Kornet
Mike Muscala
Pat Connaughton
Stanley Johnson
J.R. Smith
Ryan Arcidiacono
T.J. McConnell
Jerryd Bayless
Kenrich Williams
Wilson Chandler
Frank Ntilikina
Frank Jackson
Seth Curry
Dillon Brooks
Doug McDermott
Dwayne Bacon
Antonio Blakeney
Dirk Nowitzki
Justin Jackson
Dante Exum
Wayne Selden
Quinn Cook
Terrance Ferguson
Brandon Knight
Zhaire Smith
Ian Clark
MarShon Brooks
Billy Garrett
Jonathon Simmons
Jodie Meeks
Sterling Brown
C.J. Miles
Devin Harris
Cameron Payne
Jonas Jerebko
Troy Daniels
Tyler Dorsey
Henry Ellenson
Isaiah Canaan
Tony Snell
Aaron Holiday
Nik Stauskas
Matthew Dellavedova
Jordan McRae
Yogi Ferrell
Meyers Leonard
Mike Scott
Furkan Korkmaz
Juan Hernangómez
Elie Okobo
Grayson Allen
Chasson Randle
Raul Neto
Álex Abrines
Tim Frazier
Treveon Graham
Royce O’Neale
Jalen Jones
Brandon Sampson
Anthony Tolliver
Wesley Iwundu
Cameron Reynolds
Damion Lee
Donte DiVincenzo
Jared Dudley
Bonzie Colson
Troy Brown
Moritz Wagner
Devonte’ Graham
John Jenkins
Timothé Luwawu-Cabarrot
Theo Pinson
Lance Thomas
Jevon Carter
Shake Milton
Raymond Felton
Bruce Brown
Solomon Hill
Marcus Derrickson
Jerian Grant
Glenn Robinson
Georges Niang
Ryan Broekhoff
Abdel Nader
Dusty Hannahs
Brad Wanamaker
Amir Johnson
Ben McLemore
Thabo Sefolosha
Jimmer Fredette
Justin Anderson
Demetrius Jackson
Channing Frye
Malcolm Miller
Wesley Johnson
Chris Boucher
B.J. Johnson
Jason Smith
Jaylen Adams
Andrew Harrison
Dante Cunningham
Gary Clark
Jarell Martin
Lonnie Walker
Patrick McCaw
Jordan Loyd
James Nunnally
José Calderón
Lorenzo Brown
Deng Adel
Naz Mitrou-Long
Tyler Cavanaugh
Dwight Powell
Robin Lopez
JaMychal Green
Rondae Hollis-Jefferson
Markelle Fultz
Christian Wood
Jahlil Okafor
Maurice Harkless
Tyler Zeller
Jake Layman
Miles Bridges
Dorian Finney-Smith
Boban Marjanović
Willy Hernangómez
Luol Deng
Joakim Noah
Derrick Jones
Michael Beasley
Harry Giles
OG Anunoby
Ersan İlyasova
Evan Turner
Maxi Kleber
Michael Kidd-Gilchrist
James Ennis
Devin Robinson
Zach Collins
David Nwaba
Johnathan Williams
Gorgui Dieng
Omri Casspi
Kevon Looney
Mo Bamba
Sam Dekker
Cheick Diallo
Omari Spellman
Ivan Rabb
Ed Davis
D.J. Wilson
Andre Iguodala
Daniel Theis
Torrey Craig
Aron Baynes
John Henson
Greg Monroe
Troy Williams
Chandler Hutchison
Alex Poythress
Thon Maker
Keita Bates-Diop
Dragan Bender
Corey Brewer
Khem Birch
Michael Carter-Williams
Jonah Bolden
Alfonzo McKinnie
Jaron Blossomgame
Ian Mahinmi
Deyonta Davis
Zaza Pachulia
Salah Mejri
Pau Gasol
Jordan Bell
Tyson Chandler
Frank Mason
Luc Mbah a Moute
Johnathan Motley
Marquese Chriss
Mitch Creek
Shaun Livingston
Cristiano Felício
Courtney Lee
T.J. Leaf
Anfernee Simons
Jon Leuer
Rawle Alkins
Hamidou Diallo
Patrick Patterson
Daryl Macon
Nenê Hilário
Alan Williams
Tyrone Wallace
Isaiah Briscoe
Kyle O’Quinn
Jerome Robinson
Duncan Robinson
Semi Ojeleye
PJ Dozier
Miloš Teodosić
Sviatoslav Mykhailiuk
Daniel Hamilton
Skal Labissière
Edmond Sumner
Gary Trent
Deonte Burton
Yuta Watanabe
Udonis Haslem
Jaylen Morris
Ryan Anderson
Khyri Thomas
Guerschon Yabusele
Jared Terrell
Julian Washburn
Caleb Swanigan
Wade Baldwin
Isaiah Hartenstein
Chimezie Metu
Quincy Pondexter
Quincy Acy
Justin Patton
Thomas Welsh
Jarred Vanderbilt
Malachi Richardson
Brandon Goodwin
DeVaughn Akoon-Purcell
Sindarius Thornwell
Isaac Bonga
Alize Johnson
Ron Baker
Tahjere McCall
Ray Spalding
C.J. Williams
Džanan Musa
Haywood Highsmith
Melvin Frazier
Jacob Evans
Terrence Jones
Tyler Lydon
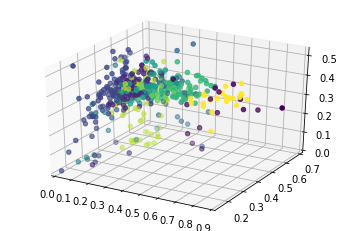
K-Means Clustering
This algorithm requires a certain number of clusters as an input – thus the “k” in “k-means” – and I used 10 to maintain consistency with the prior DBSCAN model. The 3D graph to the left shows generally similar clusters to the DBSCAN algorithm. (Arbitrarily determining how many positions each player could be classified into might’ve altered the final results, but this can be ignored given the scope of this project.)
Final Positional Clusters (K-Means Model)
James Harden
Paul George
LeBron James
Stephen Curry
Devin Booker
Kawhi Leonard
Kevin Durant
Damian Lillard
Bradley Beal
Kemba Walker
Blake Griffin
Donovan Mitchell
Kyrie Irving
Zach LaVine
Russell Westbrook
Jrue Holiday
Luka Dončić
DeMar DeRozan
Mike Conley
D’Angelo Russell
John Wall
Trae Young
Victor Oladipo
Jimmy Butler
De’Aaron Fox
Chris Paul
Kyle Lowry
Giannis Antetokounmpo
Joel Embiid
Anthony Davis
Karl-Anthony Towns
Julius Randle
LaMarcus Aldridge
Nikola Vučević
Nikola Jokić
John Collins
Andre Drummond
Ben Simmons
Deandre Ayton
DeMarcus Cousins
Jusuf Nurkić
Steven Adams
Hassan Whiteside
Klay Thompson
CJ McCollum
Buddy Hield
Lou Williams
JaKarr Sampson
Tobias Harris
Danilo Gallinari
Kyle Kuzma
Lauri Markkanen
Brandon Ingram
Khris Middleton
Jamal Murray
J.J. Redick
Andrew Wiggins
Tim Hardaway
T.J. Warren
Bojan Bogdanović
Derrick Rose
R.J. Hunter
Kevin Love
Pascal Siakam
Spencer Dinwiddie
Jordan Clarkson
Collin Sexton
Josh Richardson
Harrison Barnes
Eric Gordon
Aaron Gordon
Jayson Tatum
Malcolm Brogdon
Dennis Schröder
Reggie Jackson
Jeremy Lamb
Nikola Mirotić
Kelly Oubre
Evan Fournier
Terrence Ross
Dwyane Wade
Emmanuel Mudiay
Jabari Parker
Bobby Portis
Bogdan Bogdanović
Marcus Morris
Goran Dragić
Rudy Gay
Taurean Waller-Prince
Carmelo Anthony
Cedi Osman
Jaylen Brown
Kevin Knox
Jae Crowder
Montrezl Harrell
Jonas Valančiūnas
Serge Ibaka
Marvin Bagley
Domantas Sabonis
Jaren Jackson
Enes Kanter
Jerami Grant
Al Horford
Myles Turner
Paul Millsap
Brook Lopez
JaVale McGee
Willie Cauley-Stein
Derrick Favors
Alex Len
Jarrett Allen
Taj Gibson
Dewayne Dedmon
Dwight Powell
Thomas Bryant
Kenneth Faried
Wendell Carter
Cody Zeller
Jonathan Isaac
Nemanja Bjelica
JaMychal Green
Al-Farouq Aminu
Bam Adebayo
Rondae Hollis-Jefferson
Noah Vonleh
Bruno Caboclo
Mason Plumlee
Maurice Harkless
Maxi Kleber
Mo Bamba
Jemerrio Jones
Eric Bledsoe
Walt Lemon
Otto Porter
Caris LeVert
Dennis Smith
Marc Gasol
Robert Covington
Ricky Rubio
Thaddeus Young
Justise Winslow
Trevor Ariza
Jeff Teague
Joe Ingles
Kent Bazemore
Gordon Hayward
Josh Jackson
Kris Dunn
Darren Collison
Fred VanVleet
Shai Gilgeous-Alexander
Elfrid Payton
Justin Holiday
Lonzo Ball
Derrick White
Larry Nance
Nicolas Batum
Alex Caruso
Rajon Rondo
Tomáš Satoranský
Marcus Smart
Delon Wright
DeAndre’ Bembry
Mikal Bridges
Markelle Fultz
Kyle Anderson
Patrick Beverley
Draymond Green
P.J. Tucker
Tyus Jones
Shaquille Harrison
Cory Joseph
De’Anthony Melton
Joe Harris
Gary Harris
Jeff Green
Wesley Matthews
Dion Waiters
E’Twaun Moore
Bryn Forbes
D.J. Augustin
Will Barton
Kentavious Caldwell-Pope
Reggie Bullock
Malik Beasley
Rodney Hood
DeMarre Carroll
Trey Burke
Allonzo Trier
J.J. Barea
Tyler Johnson
Damyean Dotson
Dario Šarić
Marco Belinelli
Monte Morris
Wayne Ellington
Danny Green
Tyreke Evans
Marvin Williams
Kelly Olynyk
Patty Mills
Avery Bradley
Kadeem Allen
Kevin Huerter
Luke Kennard
Allen Crabbe
Jeremy Lin
Tony Parker
Danuel House
Shabazz Napier
Markieff Morris
Jalen Brunson
Gerald Green
Landry Shamet
Terry Rozier
Ish Smith
Malik Monk
Alec Burks
Mario Hezonja
Kyle Korver
Norman Powell
Rodions Kurucs
Trey Lyles
Langston Galloway
Darius Miller
Isaiah Thomas
Austin Rivers
Dāvis Bertāns
Seth Curry
Jamal Crawford
Garrett Temple
James Johnson
Josh Hart
Josh Okogie
Rodney McGruder
George Hill
Chandler Parsons
Shelvin Mack
Iman Shumpert
Dorian Finney-Smith
Vince Carter
Dirk Nowitzki
Lance Stephenson
Luke Kornet
Stanley Johnson
Brandon Knight
Ian Clark
Ryan Arcidiacono
J.R. Smith
C.J. Miles
Cameron Payne
Kenrich Williams
Isaiah Canaan
Frank Ntilikina
Frank Kaminsky
Christian Wood
Frank Jackson
Jake Layman
Miles Bridges
Dillon Brooks
Boban Marjanović
Antonio Blakeney
Dwayne Bacon
Willy Hernangómez
Justin Jackson
Luol Deng
Mike Muscala
Derrick Jones
OG Anunoby
Michael Beasley
Terrance Ferguson
Pat Connaughton
Wayne Selden
Dante Exum
Quinn Cook
Ersan İlyasova
Evan Turner
Michael Kidd-Gilchrist
James Ennis
Zhaire Smith
Zach Collins
MarShon Brooks
David Nwaba
Jonathon Simmons
Sterling Brown
Gorgui Dieng
T.J. McConnell
Omri Casspi
Devin Harris
Jonas Jerebko
Tyler Dorsey
Troy Daniels
Jerryd Bayless
Sam Dekker
Henry Ellenson
Wilson Chandler
Omari Spellman
Meyers Leonard
Jordan McRae
Juan Hernangómez
Furkan Korkmaz
Mike Scott
D.J. Wilson
Daniel Theis
Elie Okobo
Torrey Craig
Andre Iguodala
Aron Baynes
John Henson
Chasson Randle
Tim Frazier
Treveon Graham
Troy Williams
Royce O’Neale
Chandler Hutchison
Brandon Sampson
Frank Mason
Alex Poythress
Jalen Jones
Dragan Bender
Thon Maker
Wesley Iwundu
Keita Bates-Diop
Anthony Tolliver
Bonzie Colson
Donte DiVincenzo
Jared Dudley
Corey Brewer
Michael Carter-Williams
Troy Brown
Alfonzo McKinnie
Jonah Bolden
Lance Thomas
Shake Milton
Jevon Carter
Bruce Brown
Solomon Hill
Jaron Blossomgame
Jerian Grant
Marquese Chriss
Courtney Lee
Salah Mejri
T.J. Leaf
Amir Johnson
Pau Gasol
Thabo Sefolosha
Patrick Patterson
Isaiah Briscoe
Skal Labissière
Dante Cunningham
Robin Lopez
Jahlil Okafor
Tyler Zeller
Joakim Noah
Harry Giles
Devin Robinson
Johnathan Williams
Kevon Looney
Cheick Diallo
Ed Davis
Ivan Rabb
Greg Monroe
Khem Birch
Johnathan Motley
Mitch Creek
Ian Mahinmi
Deyonta Davis
Shaun Livingston
Cristiano Felício
Zaza Pachulia
Ray Spalding
Jon Leuer
Hamidou Diallo
Nenê Hilário
Alan Williams
Kyle O’Quinn
Jordan Bell
Tyson Chandler
Jarred Vanderbilt
Doug McDermott
Billy Garrett
Jodie Meeks
Tony Snell
Yogi Ferrell
Aaron Holiday
Nik Stauskas
Matthew Dellavedova
Grayson Allen
Álex Abrines
Raul Neto
Cameron Reynolds
Damion Lee
Moritz Wagner
John Jenkins
Devonte’ Graham
Timothé Luwawu-Cabarrot
Theo Pinson
Raymond Felton
Marcus Derrickson
Glenn Robinson
Ryan Broekhoff
Georges Niang
Abdel Nader
Dusty Hannahs
Ben McLemore
Brad Wanamaker
Anfernee Simons
Rawle Alkins
Justin Anderson
Jimmer Fredette
Demetrius Jackson
Channing Frye
Daryl Macon
Malcolm Miller
Jerome Robinson
Wesley Johnson
B.J. Johnson
Chris Boucher
Jason Smith
Semi Ojeleye
Duncan Robinson
Sviatoslav Mykhailiuk
Jaylen Adams
Miloš Teodosić
Andrew Harrison
Edmond Sumner
Gary Clark
Jarell Martin
Patrick McCaw
Yuta Watanabe
Deonte Burton
Lonnie Walker
Scott Machado
Ryan Anderson
Udonis Haslem
James Nunnally
Jordan Loyd
Khyri Thomas
José Calderón
Guerschon Yabusele
Julian Washburn
Lorenzo Brown
Caleb Swanigan
Isaiah Hartenstein
Wade Baldwin
Chimezie Metu
Quincy Pondexter
Quincy Acy
Deng Adel
Brandon Goodwin
Malachi Richardson
Naz Mitrou-Long
Sindarius Thornwell
Ron Baker
Tyler Cavanaugh
Luc Mbah a Moute
Tahjere McCall
Tyrone Wallace
PJ Dozier
Daniel Hamilton
Gary Trent
C.J. Williams
Jaylen Morris
Jared Terrell
Džanan Musa
Haywood Highsmith
Justin Patton
Thomas Welsh
Melvin Frazier
Jacob Evans
Terrence Jones
DeVaughn Akoon-Purcell
Alize Johnson
Tyler Lydon
Isaac Bonga
Hierarchical Clustering
Similar to K-Means, this algorithm takes in a certain number of clusters, and I used 10 clusters again for the same reason mentioned above. As alluded to in its name, this model creates hierarchies between data points and gradually classifies them into clusters. Each of the 10 clusters are displayed to the right.


Final Positional Clusters (Hierarchical Model)
LeBron James
Kawhi Leonard
Devin Booker
Kevin Durant
Damian Lillard
Kemba Walker
Bradley Beal
Blake Griffin
Donovan Mitchell
Kyrie Irving
Zach LaVine
Julius Randle
Luka Dončić
DeMar DeRozan
Jrue Holiday
D’Angelo Russell
Mike Conley
John Wall
Trae Young
Victor Oladipo
Jimmy Butler
Brandon Ingram
Jamal Murray
De’Aaron Fox
Ben Simmons
Josh Richardson
DeMarcus Cousins
Aaron Gordon
Chris Paul
Walt Lemon
Kyle Lowry
Marc Gasol
Draymond Green
James Harden
Paul George
Stephen Curry
Russell Westbrook
Giannis Antetokounmpo
Joel Embiid
Anthony Davis
Karl-Anthony Towns
Nikola Vučević
Nikola Jokić
Klay Thompson
CJ McCollum
Buddy Hield
Lou Williams
JaKarr Sampson
Tobias Harris
Danilo Gallinari
Lauri Markkanen
Kyle Kuzma
Khris Middleton
Tim Hardaway
J.J. Redick
Andrew Wiggins
Bojan Bogdanović
T.J. Warren
Derrick Rose
R.J. Hunter
Spencer Dinwiddie
Jordan Clarkson
Collin Sexton
Harrison Barnes
Eric Gordon
Eric Bledsoe
Jayson Tatum
Malcolm Brogdon
Dennis Schröder
Reggie Jackson
Jeremy Lamb
Kelly Oubre
Nikola Mirotić
Evan Fournier
Terrence Ross
Dwyane Wade
Emmanuel Mudiay
Bogdan Bogdanović
Otto Porter
Marcus Morris
Joe Harris
Goran Dragić
Caris LeVert
Dennis Smith
Taurean Waller-Prince
Carmelo Anthony
Robert Covington
Cedi Osman
Jaylen Brown
Gary Harris
Kevin Knox
Ricky Rubio
Justise Winslow
Trevor Ariza
Jeff Green
Jeff Teague
Joe Ingles
Dion Waiters
E’Twaun Moore
Jae Crowder
D.J. Augustin
Kent Bazemore
Will Barton
Josh Jackson
Kris Dunn
Darren Collison
DeMarre Carroll
Fred VanVleet
J.J. Barea
Tyler Johnson
Elfrid Payton
Dario Šarić
Justin Holiday
Danny Green
Tyreke Evans
Marvin Williams
Kelly Olynyk
Lonzo Ball
Kevin Huerter
Rajon Rondo
Marcus Smart
Mikal Bridges
P.J. Tucker
LaMarcus Aldridge
John Collins
Pascal Siakam
Montrezl Harrell
Deandre Ayton
Jusuf Nurkić
Jonas Valančiūnas
Serge Ibaka
Marvin Bagley
Jabari Parker
Bobby Portis
Domantas Sabonis
Jaren Jackson
Enes Kanter
Rudy Gay
Al Horford
Jerami Grant
Myles Turner
Paul Millsap
Thaddeus Young
Brook Lopez
Hassan Whiteside
JaVale McGee
Willie Cauley-Stein
Derrick Favors
Jarrett Allen
Dewayne Dedmon
Wendell Carter
Cody Zeller
Jonathan Isaac
Nemanja Bjelica
Larry Nance
JaMychal Green
Al-Farouq Aminu
Bam Adebayo
Noah Vonleh
Kyle Anderson
Mason Plumlee
Jemerrio Jones
Andre Drummond
Steven Adams
Wesley Matthews
Bryn Forbes
Gordon Hayward
Kentavious Caldwell-Pope
Malik Beasley
Reggie Bullock
Rodney Hood
Alex Len
Trey Burke
Allonzo Trier
Shai Gilgeous-Alexander
Taj Gibson
Damyean Dotson
Dwight Powell
Marco Belinelli
Thomas Bryant
Kenneth Faried
Monte Morris
Wayne Ellington
Derrick White
Avery Bradley
Patty Mills
Kadeem Allen
Luke Kennard
Jeremy Lin
Allen Crabbe
Robin Lopez
Tony Parker
Markieff Morris
Shabazz Napier
Danuel House
Jalen Brunson
Nicolas Batum
Alex Caruso
Gerald Green
Landry Shamet
Terry Rozier
Malik Monk
Tomáš Satoranský
Ish Smith
Rondae Hollis-Jefferson
Mario Hezonja
Alec Burks
Delon Wright
Frank Kaminsky
Kyle Korver
Norman Powell
Trey Lyles
Rodions Kurucs
Langston Galloway
DeAndre’ Bembry
Bruno Caboclo
Darius Miller
Markelle Fultz
Christian Wood
Jahlil Okafor
Frank Jackson
Austin Rivers
Isaiah Thomas
Dāvis Bertāns
Jamal Crawford
Seth Curry
Garrett Temple
James Johnson
Josh Hart
Maurice Harkless
Tyler Zeller
Josh Okogie
Jake Layman
Patrick Beverley
George Hill
Rodney McGruder
Shelvin Mack
Iman Shumpert
Chandler Parsons
Miles Bridges
Dorian Finney-Smith
Dillon Brooks
Vince Carter
Willy Hernangómez
Doug McDermott
Antonio Blakeney
Boban Marjanović
Dwayne Bacon
Dirk Nowitzki
Lance Stephenson
Justin Jackson
Luol Deng
Joakim Noah
OG Anunoby
Derrick Jones
Luke Kornet
Michael Beasley
Harry Giles
Mike Muscala
Terrance Ferguson
Dante Exum
Tyus Jones
Stanley Johnson
Quinn Cook
Wayne Selden
Pat Connaughton
Evan Turner
Brandon Knight
Maxi Kleber
Ersan İlyasova
Ryan Arcidiacono
Ian Clark
Michael Kidd-Gilchrist
Zhaire Smith
J.R. Smith
Devin Robinson
James Ennis
MarShon Brooks
Zach Collins
Jonathon Simmons
Cory Joseph
Shaquille Harrison
David Nwaba
Billy Garrett
Johnathan Williams
Jodie Meeks
C.J. Miles
Sterling Brown
T.J. McConnell
Gorgui Dieng
Omri Casspi
Devin Harris
Kevon Looney
Jonas Jerebko
Cameron Payne
Troy Daniels
Mo Bamba
Tyler Dorsey
Jerryd Bayless
Kenrich Williams
Sam Dekker
Wilson Chandler
Isaiah Canaan
Cheick Diallo
Tony Snell
Henry Ellenson
Yogi Ferrell
Jordan McRae
Meyers Leonard
Aaron Holiday
Nik Stauskas
Matthew Dellavedova
Omari Spellman
D.J. Wilson
Mike Scott
Furkan Korkmaz
Juan Hernangómez
Ed Davis
Ivan Rabb
Elie Okobo
Daniel Theis
Andre Iguodala
Frank Ntilikina
Torrey Craig
John Henson
Aron Baynes
Grayson Allen
Chasson Randle
Raul Neto
Greg Monroe
Troy Williams
Álex Abrines
Treveon Graham
Tim Frazier
Royce O’Neale
Chandler Hutchison
Brandon Sampson
Frank Mason
Alex Poythress
Jalen Jones
Thon Maker
Wesley Iwundu
Keita Bates-Diop
Dragan Bender
Anthony Tolliver
De’Anthony Melton
Cameron Reynolds
Bonzie Colson
Jared Dudley
Corey Brewer
Donte DiVincenzo
Damion Lee
Khem Birch
Troy Brown
Moritz Wagner
Michael Carter-Williams
John Jenkins
Alfonzo McKinnie
Jonah Bolden
Devonte’ Graham
Johnathan Motley
Timothé Luwawu-Cabarrot
Theo Pinson
Lance Thomas
Shake Milton
Jevon Carter
Bruce Brown
Solomon Hill
Raymond Felton
Jaron Blossomgame
Mitch Creek
Glenn Robinson
Marcus Derrickson
Jerian Grant
Marquese Chriss
Ian Mahinmi
Deyonta Davis
Dusty Hannahs
Cristiano Felício
Ryan Broekhoff
Shaun Livingston
Courtney Lee
Abdel Nader
Georges Niang
Amir Johnson
Pau Gasol
Brad Wanamaker
Salah Mejri
T.J. Leaf
Ray Spalding
Zaza Pachulia
Jon Leuer
Thabo Sefolosha
Demetrius Jackson
Justin Anderson
Jimmer Fredette
Channing Frye
Alan Williams
Nenê Hilário
Malcolm Miller
Kyle O’Quinn
Wesley Johnson
Jordan Bell
Jason Smith
Chris Boucher
B.J. Johnson
Andrew Harrison
Jaylen Adams
Tyson Chandler
Skal Labissière
Dante Cunningham
Gary Clark
Jarell Martin
Lonnie Walker
Patrick McCaw
James Nunnally
Jordan Loyd
José Calderón
Julian Washburn
Lorenzo Brown
Wade Baldwin
Isaiah Hartenstein
Quincy Pondexter
Deng Adel
Jarred Vanderbilt
Malachi Richardson
Brandon Goodwin
Naz Mitrou-Long
Sindarius Thornwell
Ron Baker
Tyler Cavanaugh
Luc Mbah a Moute
Tahjere McCall
Ben McLemore
Anfernee Simons
Rawle Alkins
Hamidou Diallo
Patrick Patterson
Daryl Macon
Isaiah Briscoe
Tyrone Wallace
Jerome Robinson
Duncan Robinson
Semi Ojeleye
Miloš Teodosić
Sviatoslav Mykhailiuk
PJ Dozier
Daniel Hamilton
Edmond Sumner
Gary Trent
Yuta Watanabe
Deonte Burton
C.J. Williams
Jaylen Morris
Ryan Anderson
Udonis Haslem
Guerschon Yabusele
Khyri Thomas
Jared Terrell
Džanan Musa
Caleb Swanigan
Chimezie Metu
Haywood Highsmith
Justin Patton
Quincy Acy
Thomas Welsh
Melvin Frazier
Jacob Evans
DeVaughn Akoon-Purcell
Terrence Jones
Tyler Lydon
Alize Johnson
Isaac Bonga
Kevin Love
Scott Machado
Conclusion
For the most part, all three models pass the eyeball test and yield reasonable player classifications, but closer examination raises some questions. The DBSCAN model effectively identifies superstars and 3-point shooters, but bench players are somewhat scattered across over half a dozen clusters. The k-means model seem to make the distinction between starters and bench players, yet there are six role player categories that don’t have any substantial or apparent differences between them. Lastly, the hierarchical model may be the most accurate, roughly separating players into the five traditional positions as well as including more specific clusters such as rebounding machines; it should also be noted that having two respective classifications for Kevin Love and Scott Machado alone is slightly confusing.
Natural forwards like Nikola Jokić are beginning to play like point guards and tiptoe the line between guards and forwards, and guards like Russell Westbrook and James Harden are surely confusing models by filling the stat sheet in unfamiliar ways for their position. As a result, there are clear disadvantages to each model used above; for example, in the k-means model, prescribing the amount of clusters may force the algorithm to classify two drastically different players as similar to best fit all the other clusters. Regardless, the high degree of variation certainly demonstrates that in the modern NBA, positions simply matter less.